물리적 데이터 모델링
논리적 데이터 모델링에서 만든 이상적인 표를 구체적인 제품에 맞는 현실적인 표로 만드는 과정
성능이 중요하다!
일단 운영해보고 데이터가 쌓인 후 부하가 큰 부분이 병목현상이 생기는지 확인
find slow query
성능을 향상시키는 방법
-인덱스 : 읽기성능 향상, 쓰기성능 저하, 저장공간 많이 차지함
-애플리케이션 : 캐시(cache) 사용해 데이터베이스 부하 줄임
(cache: 입력에 따른 실행결과 저장해두고 이후 동일한 입력에 대해 저장해둔 결과 출력하는 것)
-역정규화(다른 수단들을 시도해도 개선되지 않을 때 사용함. 단점이 많음)
역정규화(반정규화, denormalization)
정규화를 통해 만든 이상적인 표를 성능이나 개발의 편의성을 위해 표를 조작하는 것.
정규화 : 빠른 쓰기 위해 읽기 성능 희생 (읽을 때 join필요)
역정규화 : 빠른 읽기 위해 쓰기 성능 희생, 많은 저장공간 필요, 시스템이 복잡해진다
처음부터 역정규화를 하는 것이 아니라, 정규화를 제대로 실행한 뒤 성능개선을 위해 역정규화를 수행하는 것이다.
역정규화에는 엄격한 과정(법칙)이 정해져 있지 않다. 자유롭게 가능하다
역정규화 방법

1. 컬럼의 역정규화 - JOIN을 줄인다
중복값이 발생하지만 JOIN을 하지 않고 데이터를 다룰 수 있게된다. 처리 속도가 훨씬 빨라진다.
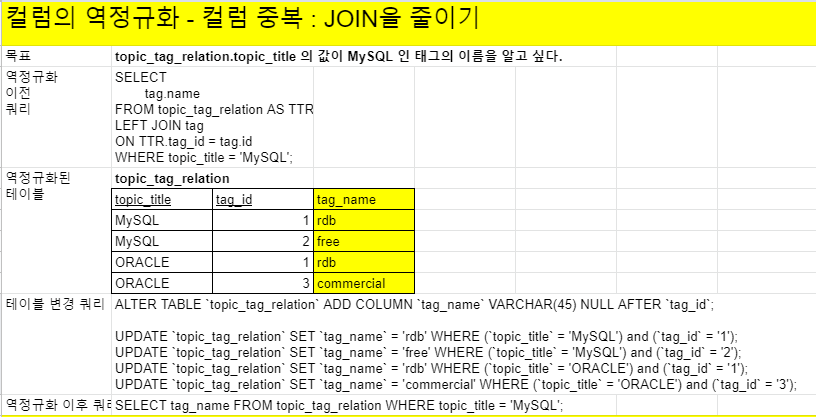
2. 테이블의 역정규화
- 컬럼을 기준으로 테이블을 분리한다
같이 사용하는 일이 많은 컬럼들끼리 테이블을 따로 만들어준다.
한 대에서 처리하던 연산들이 여러 대로 나눠서 처리할 수 있으므로 부하가 줄어들어 성능이 개선된다.
- 행을 기준으로 테이블을 분리한다
행이 아주 많을 때 사용한다.
관리가 어렵고 사고 위험이 높다.
대체로 여러 대의 서버로 분산할 때 사용할 수 있는 방법

3. 관계의 역정규화 - JOIN을 줄여 지름길을 만든다
Foreign Key 추가 -> 역정규화 줄임
author별로 tag를 확인할 경우 -> JOIN이 여러 번 일어나서 성능이 저하됨

'DATABASE' 카테고리의 다른 글
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 논리적 데이터 모델링 (0) | 2021.05.19 |
|---|---|
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 개념적 데이터 모델링 (0) | 2021.05.19 |
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 데이터 모델링의 순서, 업무파악 (0) | 2021.04.22 |
| 생활코딩 DATABASE - Join (0) | 2021.04.21 |
| 생활코딩 - DATABASE2 MySQL (0) | 2021.04.12 |