논리적 데이터 모델링
개념적 데이터 모델링에서 정의한 개념을 관계형 데이터 베이스에 맞게 데이터 형직을 잘 정리정돈 하는 것.
Mapping Rule
ERD -> 관계형 데이터 베이스에 맞는 형식으로 전환할 때 사용하는 방법론.
① Entity → Table
② Attribute → Column
③ Relation → PK, FK

위의 ERD로 관계형 데이터베이스 형식에 맞게 전환해본다.
① Entity → Table
저자, 글, 댓글 테이블을 만든다.
② Attribute → Column
attribute들의 도메인에 맞게 Column을 만든다.
속성의 제약조건들(Primary key여부, unique, auto_increasement, type)에 맞게 만든다.
이 과정을 column에 대한 도메인을 설정한다고 말한다.

③ Relation → PK, FK
1:1관계의 처리
author(저자)와 dormant(휴면자)의 관계
어떤 테이블에 PK, FK를 설정할 지 정해야 한다.
author은 dormant가 없이 tuple을 계속 생성할 수 있다.
하지만 dormant는 author에 없는 id로는 tuple을 생성할 수 없다.(author가 id=3까지 있으면 dormant에서는 id=4인 tuple생성 불가) 왜냐하면 저자가 생성되고 나서 휴면자를 설정하기 때문이다. 생성되지 않은 저자는 휴면자로 생성될 수 없다.
그러므로 휴면자가 저자에 의존적인 관계이므로 author에 PK를, dormant의 id를 FK로 설정한다.
1:N관계의 처리
1인 테이블이 PK, N인 테이블에 FK를 부여해서 서로 연관관계를 만들어준다.
N:M관계의 처리
author-topic의 관계가 M:N 관계이다(유저는 여러 개의 글을 쓸 수 있고, 여러 유저가 한 글을 공동으로 쓸 수 있는 경우)
kim: MySQL, SQL Server, ORACLE
lee: MySQL, SQL Server
라는 글을 작성했다고 했을 때,
author 테이블이나 topic 테이블에 행을 추가하면 다음과 같다.
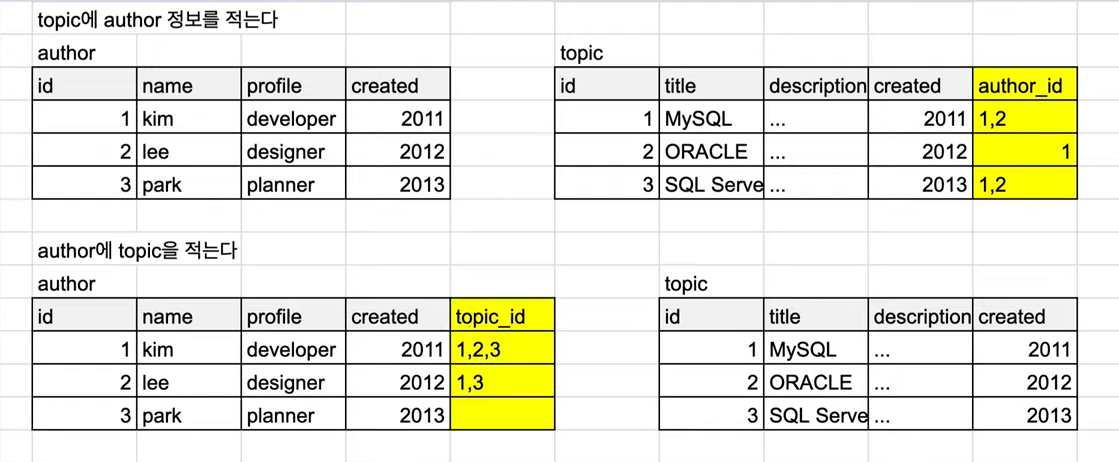
값이 1,2 이런식으로 여러 개의 값을 가지게 되면서 join이 불가능해지고, where을 통해 데이터를 찾을 때도 사용할 수 없게 된다.
=> M:N의 관계에서는 둘 사이를 연걸해주는 테이블을 만들어준다.(Mapping Table)
write라는 mapping table을 추가한 상태.
mapping table에는 두 개의 테이블(author, topic)이 결합됐을 때 의미있는 정보들을 추가할 수 있다.(created: 작성일)
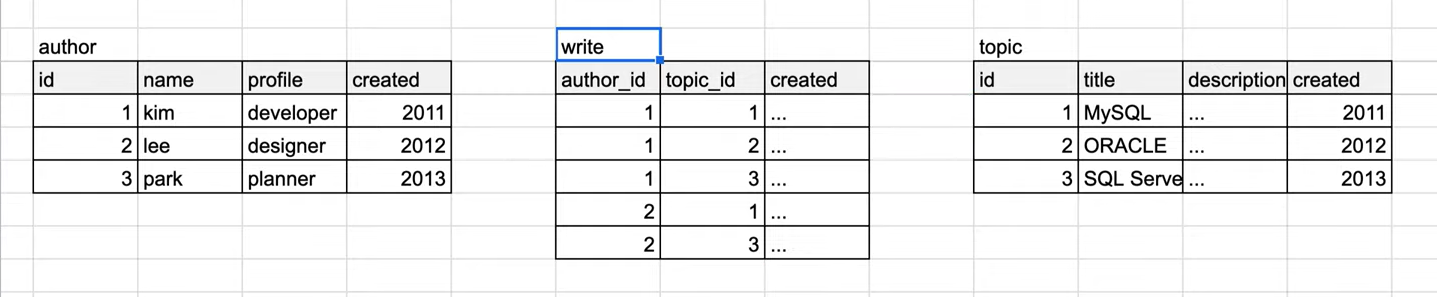
ERD에서는 따로 mapping table을 표시할 필요가 없다. M:N관계면 자연스럽게 mapping table을 추가하기 때문이다.
스키마에 반영
저자에게 글작성은 옵션, 글작성에 저자는 필수
write(0..N) ---- (1) author
토픽에게 글작성은 필수, 글작성에 토픽도 필수
write(1..N) ---- (1) topic

정규화
자료들을 모아둔 표를 관계형 데이터 베이스에게 맞는 표로 만들어주는는 것.
제3정규형까지를 산업적으로 많이 사용한다.

UNF(정규화 되지 않은 표)에서 1NF(제1정규형)이 되려면
Atomic Columns라는 조건을 만족해야 한다.
3차 정규형 릴레이션이 되려면 1차, 2차, 3차 정규형의 조건을 모두 만족해야 한다.
그러므로 순차적으로 UNF →1차→2차→3차 정규형으로 변환해야 가능하다.
아래와 같이 정규화 과정을 나타낼 수 있다.

제 1 정규화 - Atomic Columns
각 행의 각 컬럼의 값들이 모두 원자적이어야 한다
여러개의 값이 합쳐져 고유의 값을 가진다면 굳이 나눌 필요가 없다.
하지만 SELECT, ORDER BY, JOIN을 사용할 수 없다.
topic 과 tag 를 다른 테이블로 나눌 경우, n:m의 관계이므로 단순하게 나눌 수 없고 mapping table을 따로 만들어줘야 한다.

잘못된 정규화 방법
처음 테이블에 tag 컬럼에 값을 하나씩 적어 여러 행을 만들 경우 -> 데이터의 중복이 많아진다
처음 테이블에 tag1, tag2 컬럼을 만들 경우 -> tag가 하나인 경우 tag2, tag3에는 null값이 만들어지고, 검색이 어렵다. 또한 tag의 갯수가 늘어난다면 전체 테이블의 컬럼을 하나 추가해야된다.
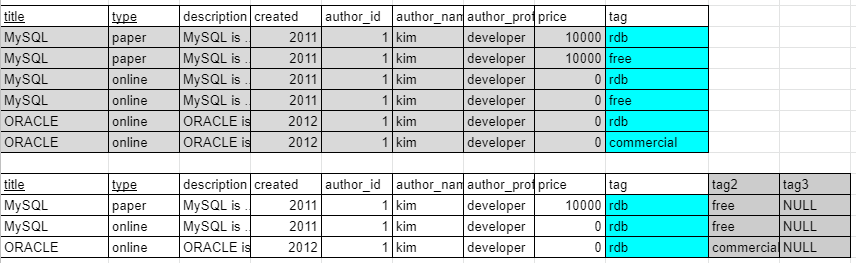
제2정규화 - No partial dependencies
부분 종속성이 없어야 한다
중복키가 있는지 확인
중복이 있다 = 부분종속성 때문
행의 일부가 동일한 행들이 존재함(전체가 같은 것은 아님)
description ~ author_profile column들은 title column에만 종속된다.
price column때문에 중복값이 생성되었다.
①title → description ~ author_profile
②type → price
에 영향을 주니까 하나의 topic table을 ①과 ②로 나누고, 중복된 행을 제거한다.

제3정규화 - No transitive dependencies
이행적 종속성 제거
author_id 는 title에 종속되지만
author_name, author_profile은 title이 아닌 author_id에 종속된다.(PK에 종속되지 않음)

author_id가 없으면 이행적 종속성이 보이지 않을 수 있지만 암시적으로 자신의 식별자를 가지고 있다고 생각하면 이행적 종속성을 쉽게 찾을 수 있다. 혹은 접두사를 확인할 것.(author_로 시작하는 column들)
'DATABASE' 카테고리의 다른 글
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 물리적 데이터 모델링 (0) | 2021.05.27 |
|---|---|
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 개념적 데이터 모델링 (0) | 2021.05.19 |
| 생활코딩 - DATABASE 관계형 데이터 모델링 - 데이터 모델링의 순서, 업무파악 (0) | 2021.04.22 |
| 생활코딩 DATABASE - Join (0) | 2021.04.21 |
| 생활코딩 - DATABASE2 MySQL (0) | 2021.04.12 |