그룹단어체커
https://www.acmicpc.net/problem/1316
1316번: 그룹 단어 체커
그룹 단어란 단어에 존재하는 모든 문자에 대해서, 각 문자가 연속해서 나타나는 경우만을 말한다. 예를 들면, ccazzzzbb는 c, a, z, b가 모두 연속해서 나타나고, kin도 k, i, n이 연속해서 나타나기 때
www.acmicpc.net
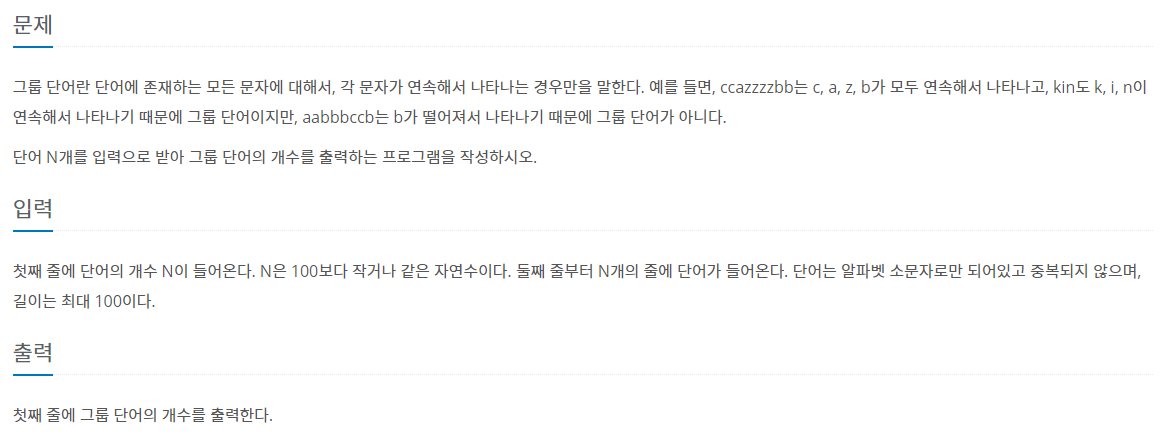
내가 작성한 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def list_overlap_del(input_list):
result_list = []
result_list.append(input_list[0])
for i in range(len(input_list)):
if result_list[-1] != input_list[i]:
result_list.append(input_list[i])
return result_list
n = int(input())
data = []
for i in range(n):
data.append(input())
count = 0
for string in data:
string_list = list(string)
string_set = set(string_list)
del_list = list_overlap_del(string_list)
if len(string_set) == len(del_list):
count += 1
print(count)
|
cs |
list_overlap_del() 함수를 만든다.
같은 알파벳이 연달아 있는 경우, 하나만 남기고 나머지는 삭제하는 함수이다.
(aabbb -> ab, aabba -> aba)
입력받은 단어들을 data라는 list에 넣는다.
for문을 사용해 하나씩 그룹단어인지 확인한다.
입력받은 문자를 list로 만든다.
list를 set형태로 바꾼 것과(string_set), list_overlap_del()함수에 넣어서 만든 것(del_list)의 길이를 비교한다.
그룹단어라면 중복값을 제거한 string_set과 알파벳의 개수가 같아야 한다.
같은 경우 count의 값을 하나 증가시킨다.
모든 단어를 확인한 후 count의 값을 화변에 출력한다.
알파벳을 하나씩 검사하기 위해 list형태로 바꿔서 list_overlap_del()에 넣었는데, 생각해보니 문자형으로 해도 슬라이싱이나 인덱싱을 할 수 있으므로 상관없는 것 같다.
다른 방법
|
1
2
3
4
5
6
7
8
9
10
11
12
|
N = int(input())
cnt = N
for _ in range(N):
word = input()
length = len(word)
for i in range(length - 1):
if word[i] == word[i + 1]:
pass
elif word[i] in word[i + 1:]:
cnt -= 1
break
print(cnt)
|
cs |
총 입력한 단어의 개수를 cnt에 대입한 후, 그룹단어가 아닐 경우 cnt의 값을 하나씩 감소시켜 그룹단어의 수를 구한다.
단어의 첫번째 알파벳부터 확인하는데 다음 알파벳과 같으면 pass, 다르면 그 이후에도 알파벳이 다시 나오는지 확인한다. 알파벳이 다시 나오면 cnt 값을 1 감소시키고 break로 for문을 빠져나간다.
* 단어를 하나씩 확인할 때, 굳이 list형으로 변환시킬 이유가 없다.
* 조금 더 쉬운 방법이 없는지 생각해보자(word[i] in word[i + 1:])
'알고리즘' 카테고리의 다른 글
| 백준 - 10250번 (0) | 2021.08.03 |
|---|---|
| 백준 - 2869번 (0) | 2021.08.03 |
| 백준 - 2941번 / replace() (0) | 2021.08.02 |
| 백준 - 5622번 / find(), index(), list comprehension (0) | 2021.08.02 |
| 백준 - 2908번 / python slicing (0) | 2021.08.02 |